
Una collaborazione per accelerare la ricerca con modelli non vincolati ad una specifica programmazione, ma all’adattamento in vari scenari.
I robot sono abili specialisti, ma scarsi come operatori generalisti. Abitualmente, è necessario addestrare un modello per ogni attività ed ambiente, con la difficoltà che spesso la modifica di una singola variabile richiede d’iniziare da zero.
Costruire un set di dati è il passaggio indispensabile per sviluppare un modello generalista efficace in grado di controllare diversi robot con istruzioni differenziate ed eseguire ragionamenti di base su compiti complessi. Tuttavia, una raccolta di questo tipo richiede un dispendio di risorse eccessivo per un solo ente.

Open X-Embodiment Dataset è il maggiore dataset, condiviso gratuitamente, di robot reali mai realizzato riunendo 60 set di 34 laboratori di ricerca in tutto il mondo, per un totale di oltre 1 milione di traiettorie reali (suddivise in più di 500 competenze e 150.000 attività) che abbracciano 22 forme, dai singoli bracci robotici ad esemplari bimanuali o quadrupedi.
Fra le organizzazioni coinvolte si trovano l’ETH di Zurigo e l’Istituto Italiano di Tecnologia.
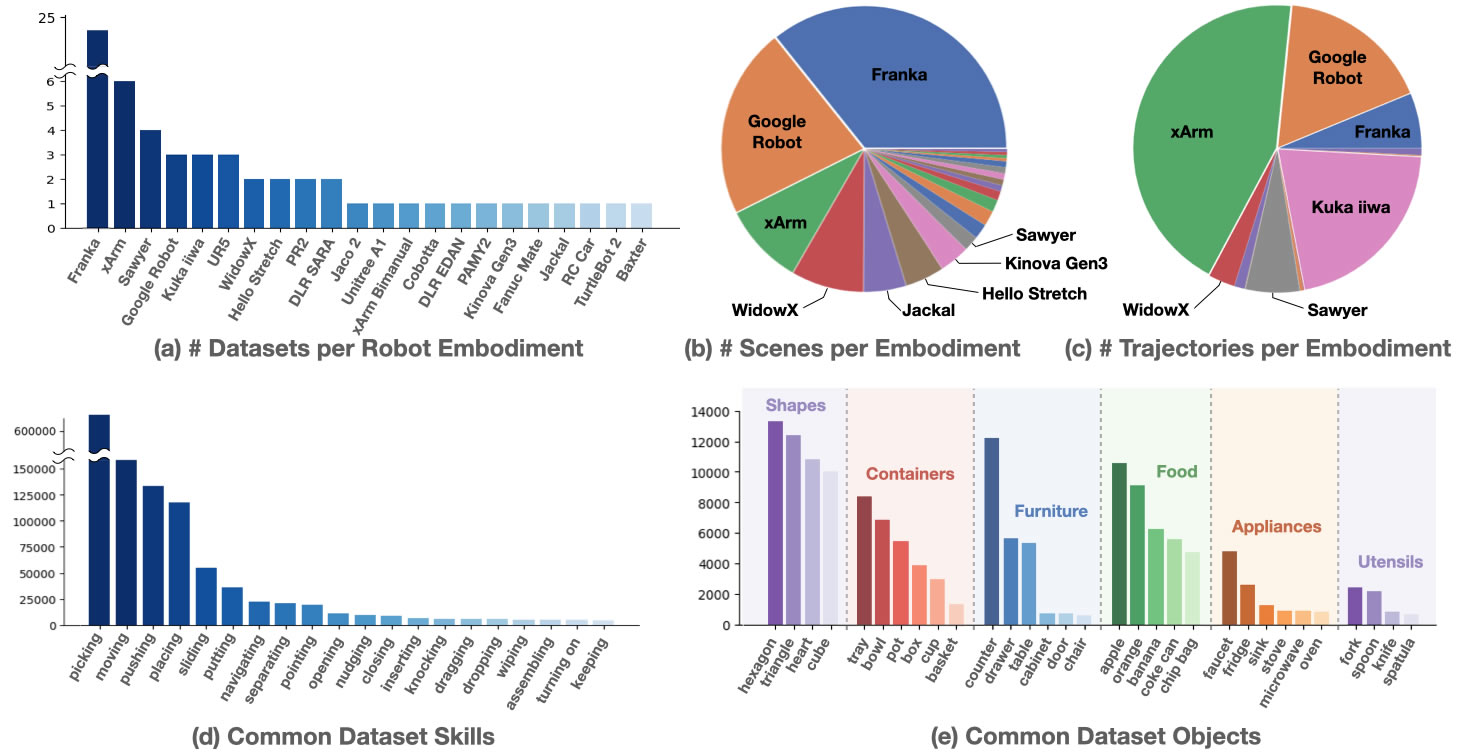
L’accessibilità è garantita usando il formato RLDS, compatibile con la maggior parte dei framework di deep learning.
RLDS sta per Reinforcement Learning Datasets ed è un ecosistema di strumenti per archiviare, recuperare e manipolare dati episodici nel contesto del processo decisionale sequenziale, incluso l’apprendimento per rinforzo (RL), l’apprendimento per dimostrazioni, l’RL offline o l’apprendimento per imitazione.
Il modello di trasformatore robotico RT-X nasce dalla collaborazione tra DeepMind e 33 istituti accademici. L’ultimo rilascio è un’evoluzione dei precedenti RT-1 e RT-2.
RT-1: funziona su un’architettura Transformer, un approccio nell’apprendimento automatico progettato per il controllo robotico del mondo reale su larga scala. Il modello utilizza input visivi e li elabora attraverso un modello pre-addestrato come EfficientNet. Le azioni sono guidate anche da istruzioni in linguaggio naturale trasformate in incorporamenti per processi che permettono di prendere decisioni informate sulle azioni del robot nel suo ambiente.
RT-2 : è un modello visione-linguaggio-azione (VLA) che unisce dati visivi e linguistici trasmettendo le azioni del robot come token del linguaggio naturale.
L’adattabilità rimane un fattore chiave.
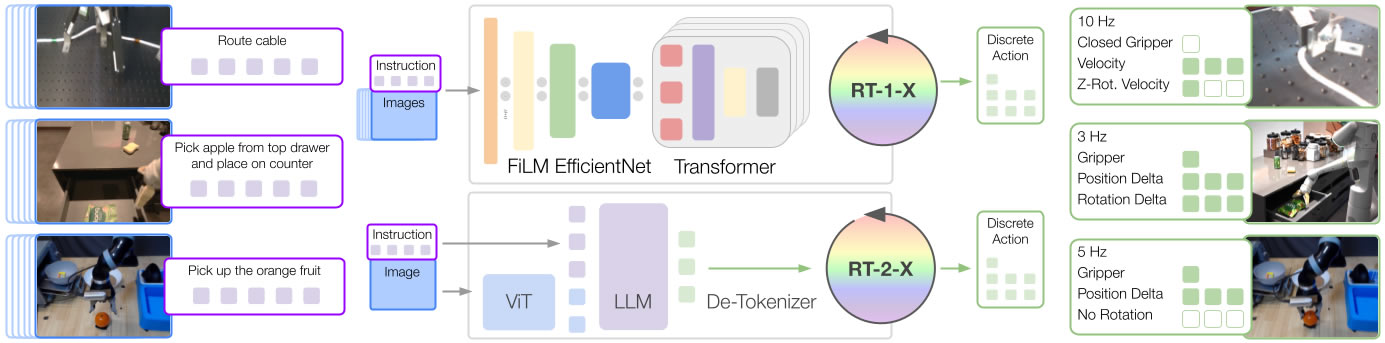
RT-1-X è stato impiegato per eseguire diversi compiti in 6 laboratori superando del 50% i metodi RT-1 o quelli originali addestrati su set di dati individuali in domini di piccole dimensioni.
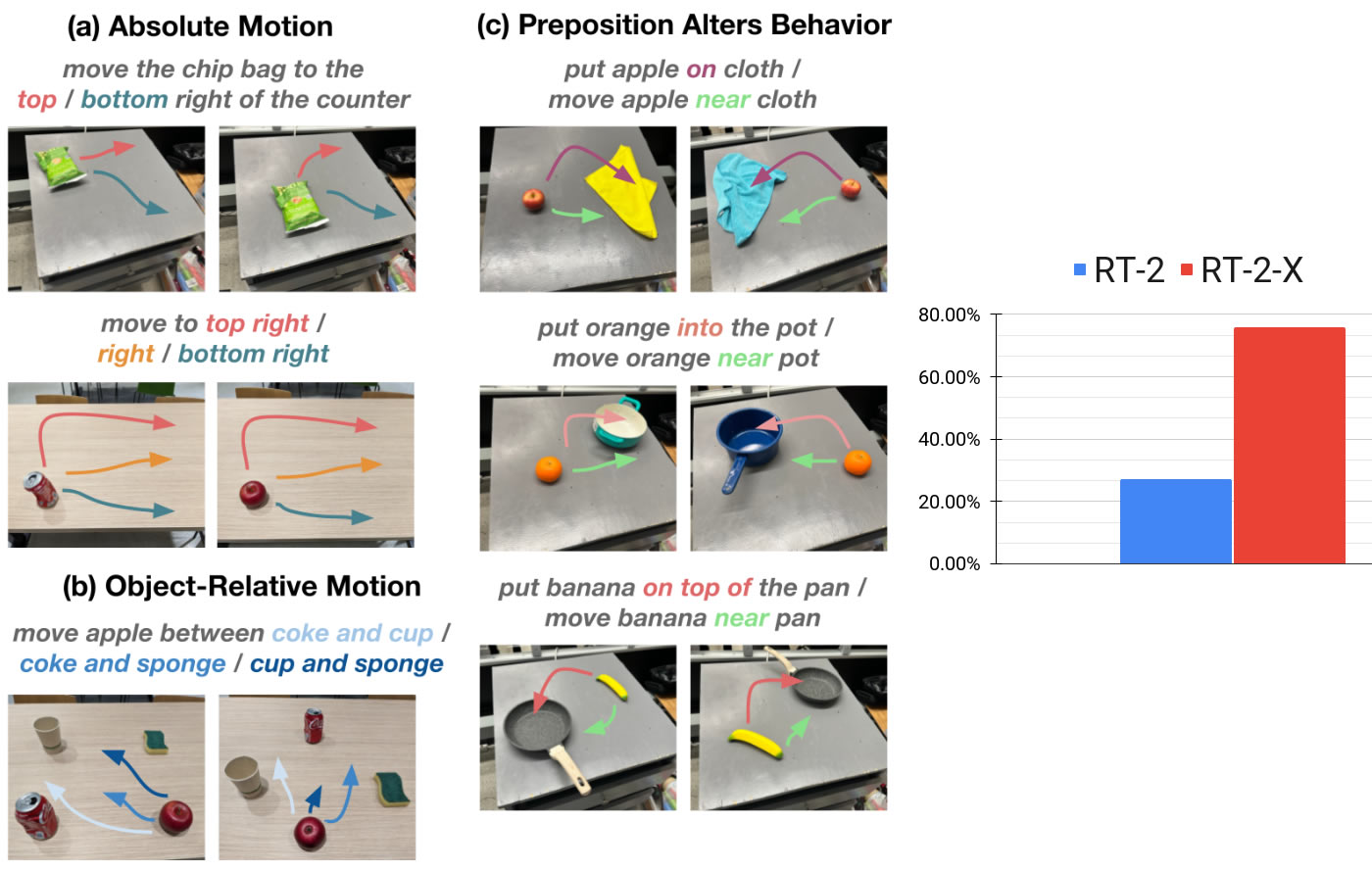
RT-2-X supera RT-2 di 3 volte nelle valutazioni delle abilità emergenti dimostrando capacità che RT-2 non aveva, inclusa una migliore comprensione spaziale sia in senso assoluto che relativo. Piccoli cambiamenti nella preposizione nella sequenza delle attività possono anche modulare il comportamento del robot di basso livello
Un elenco dettagliato di tutti i dataset è consultabile su un foglio di Google.
RIPRODUZIONE RISERVATA – © 2024 SHOWTECHIES – Quando la Tecnologia è spettacolo™ – E’ vietata la riproduzione e redistribuzione, anche parziale, dell’articolo senza autorizzazione scritta. Se desideri riprodurre i contenuti pubblicati, contattaci.
Immagini ed infografica: Google DeepMind – Open X-Embodiment



Commenta per primo