_SBraga")
Il team DeepMind ha presentato un mondo completamente nuovo capace di convertire una varietà d’informazioni in ambienti interattivi, facili da creare ed esplorare partendo da una sola immagine o da un testo descrittivo.
L’Intelligenza Artificiale generativa si è diffusa negli ultimi anni con modelli in grado di originare contenuti attraverso linguaggio, immagini e persino video. Google DeepMind ha pubblicato uno studio su Generative Interactive Environments in cui ambienti interattivi e riproducibili possono essere realizzati per mezzo di un’interfaccia di azione latente.
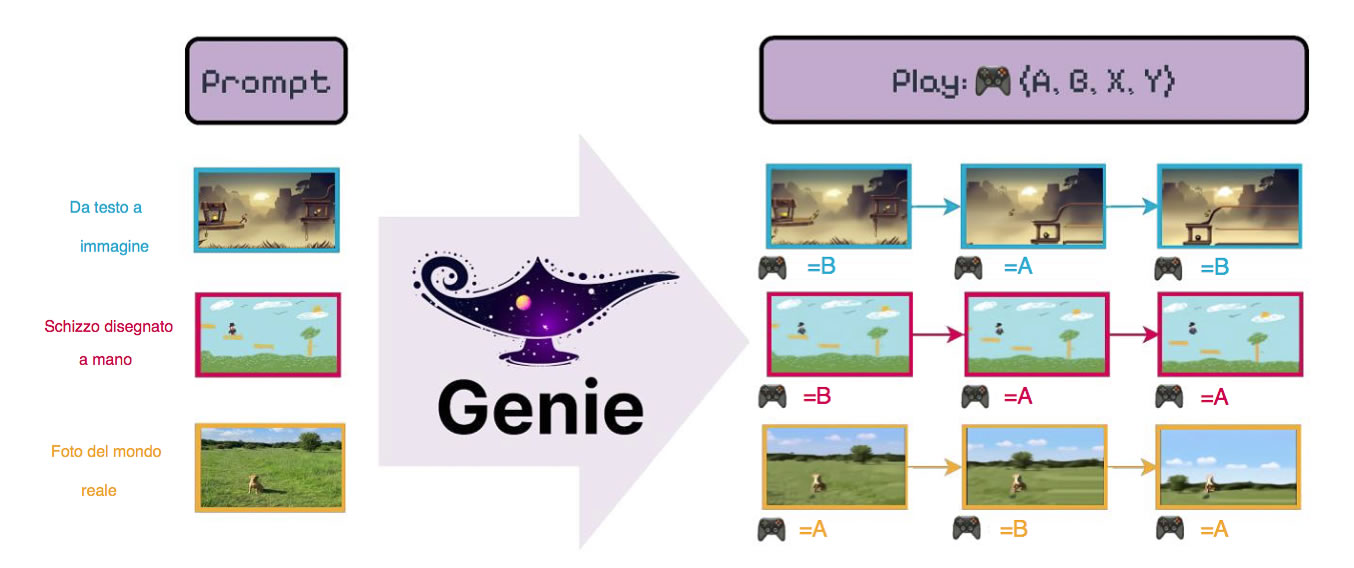
Genie è addestrato da un vasto set di dati, oltre 200.000 ore di videogiochi 2D pubblicamente accessibili ed è controllabile, fotogramma per fotogramma, nonostante la formazione senza azioni o etichette di testo.
Il set di dati è stato filtrato per parole chiave ottenendo 55 milioni di videoclip da 16 secondi a 10 FPS, con risoluzione 160 x 90, per un totale finale di 6,8 milioni di videoclip da 16 secondi (30.000 ore).
Quello che rende Genie unico è la capacità d’imparare controlli dettagliati dai video in Internet, generalmente senza etichette relative all’azione eseguita o alla parte d’immagine da esaminare.
Sorprendentemente, Genie apprende non solo quali sezioni di un’osservazione sono comunemente verificabili, ma deduce diverse azioni latenti coerenti negli ambienti generati, con output simili da prompt differenti.

Basta una sola immagine per creare un ambiente interattivo totalmente nuovo. Questo fatto si presta ad una varietà di mondi virtuali, ad esempio, impiegando un modello di generazione di testo-immagine all’avanguardia per produrre fotogrammi iniziali da passare poi a Genie che si basa su trasformatori spazio-temporali (ST) in tutti i componenti. Il modello utilizza un tokenizzatore video ed estrae azioni latenti attraverso un modello di azione causale.
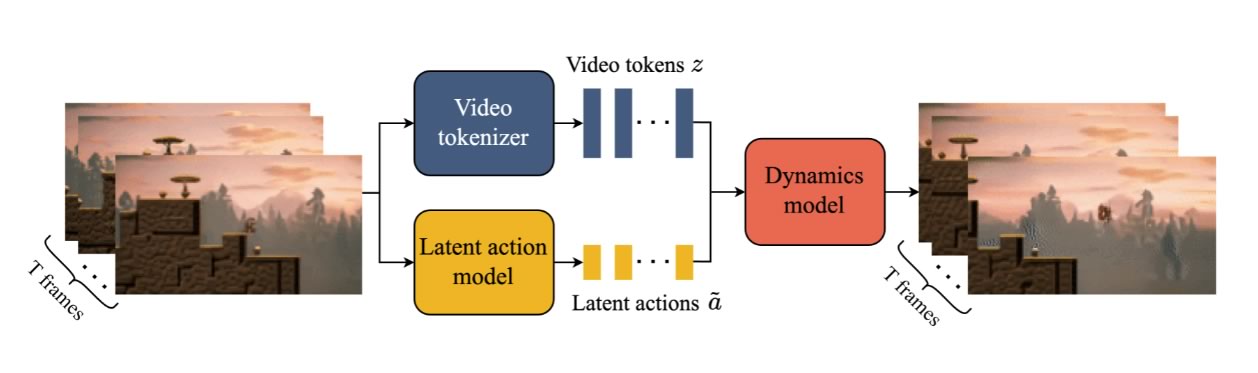
In pratica il Video Tokenizer elabora i dati video suddividendoli in “token” comprensibili per il Genio. Poi subentra la fase del modello ad azione latente che analizza le transizioni fra fotogrammi consecutivi identificando azioni fondamentali per l’interazione, come correre e saltare. Il modello dinamico genera previsioni per i fotogrammi successivi.
Il modello viene addestrato in due fasi seguendo una pipeline di generazione video auto-regressiva standard. Prima il tokenizzatore video è utilizzato per il modello dinamico, poi si co-addestra il modello di azione latente, direttamente dai pixel ed il modello dinamico (sui token video).
Genie può essere attivato con immagini inedite, come fotografie o disegni del mondo reale, consentendo alle persone d’interagire con i loro mondi virtuali inventati.
Gli sviluppatori si sono concentrati su giochi e robotica, ma l’architettura non è settoriale e dovrebbe funzionare per qualsiasi tipo di dominio, senza richiedere alcuna conoscenza aggiuntiva, in maniera scalabile su set di dati in rete sempre maggiori.
Genie può anche simulare oggetti deformabili, un compito normalmente impegnativo che può essere appreso dai dati.
Rimane un abisso tra il livello delle interazioni ed il coinvolgimento di modelli generativi video e strumenti linguistici come ChatGPT, per non parlare di altre esperienze immersive.
La risorsa è ancora in fase di sviluppo e, per ora, è riservata solo ai ricercatori.
Genie eredita alcune delle debolezze di altri modelli di trasformatori auto-regressivi e può avere allucinazioni future non realistiche. Pur avendo fatto progressi con le rappresentazioni spazio-temporali, si limita a 16 fotogrammi, cosa che rende difficile ricavare ambienti coerenti su lunghi orizzonti. Infine, Genie attualmente opera a circa 1 FPS e richiede futuri progressi per un frame rate efficiente per l’interazione.
Data la sua universalità, il modello ha grandi potenzialità e potrebbe essere addestrato da una maggiore quantità di video Internet per simulare ambienti distinti, realistici ed immaginari. Uno dei limiti principali è la mancanza di diversificazione per addestrare agenti, ma si potrebbero sbloccare nuovi percorsi. Dietro le scelte esistono motivazioni etiche, ma forse anche questioni legali.
Trovate la documentazione su Genie a questo link.
Il team di geni (per ora ancora umani) dietro quest’incredibile avanzamento dell’AI è formato da: Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Singh, Tim Rocktäschel
RIPRODUZIONE RISERVATA – © 2024 SHOWTECHIES – Quando la Tecnologia è spettacolo™
Immagini/Grafica: Google DeepMind – elaborazione grafica di copertina Simona Braga per ShowTechies su immagine generata con script AI



Un programma di AI che genera videogiochi con zero esperienza è incredibile!